Recurring Neural Networks and Star Trek
Earlier this year I wrote about Convolutional Neural Networks (CNNs) and their applications to image classification.
As I discussed, CNNs are very powerful for image classification, giving better-than-human results in some cases, however they do not provide a singular solution to any given problem.
One limitation of CNNs is that they have no notion of time or sequences, that is to say that each prediction is totally independent of any previous predictions.
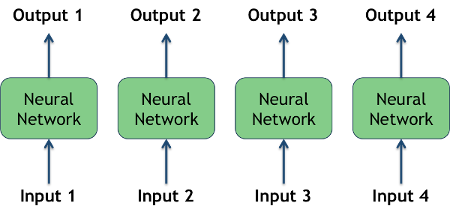
In the diagram above, each input gives an output independent of the other inputs; one could change the order of the inputs and expect to obtain the same output.
However there are many types of problems for which we may wish to apply machine learning and neural network-based models, but where we need the ability to process and recognize time-dependent sequences.
One such example is language translation where you might try and process sentences one word at a time, and where the translation of a particular word will depend on the words that came before.
Similarly, if you want to build a model to describe a scene in an image word-by-word, then you would want the ability to take previous words into account as the model generates the description.
In fact, these sorts of sequential models are useful for many different problems in Natural Language Processing, as language is inherently sequential and highly context-dependent.
In this post I will focus on a particular application called Character Level Language modeling where the aim is to build a model capable of generating text one character at a time.
The approach used is based on supervised learning, and as such we need a training dataset. For this exercise I decided to use the complete scripts of Star Trek: The Next Generation.
As with the post on CNNs, I will try and keep the explanations relatively non-technical while still getting across the key ideas. If you just want to see the output, you can skip straight to the results section.
- Brief Introduction to Recurring Neural Networks
- Baseline Results Using Markov Chain Models
- Star Trek Script Generation Using RNNs
1. Brief Introduction to Recurring Neural Networks
Fully Connected Neural Networks
Let's start with a quick reminder of what fully-connected neural networks look like.
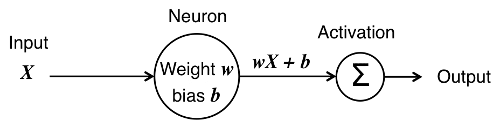
The picture above depicts a single 'neuron' which at its core is nothing more than a function which:
- Receives input X
- Calculate the linear transform wX + b
- Passes the result through an activation function, ∑, in order to produce the output of the neuron
The idea of the activation function is to add complexity to the model and ensure that neurons do not 'fire' (produce output) all of the time, but only some of the time based on certain conditions.
The activation functions used in practice often look like these:
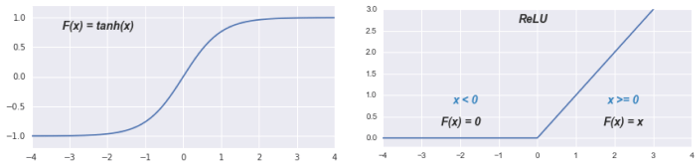
A fully-connected neural network is created by combining many of these neurons into layers, and connecting the layers together in such a way that in each layer (except the input and output layers) every neuron is connected to every other neuron in the preceding and following layers.
Recurring Neural Networks
If we were to use the neuron above for processing a sequence of inputs, $ x_1, x_2, x_3,... $, it is clear that the model cannot take into account any notion of order or context, as at each step the output is dependent only upon the current input $ x_t $ and the internal parameters.
What we need instead is a model that take into account both the current input $ x_t $ as well as all of the previous inputs up until that point:
Recurring Neural Networks (RNNs) provide exactly this type of model. The simplest RNN is based on the following set-up:

Here the model has an internal state $ h_t $ which is updated at each time step according to a recurrence relation:
That is to say that the hidden state at time t is a function of the previous hidden state at time t-1 along with the input $ x_t $, with $ h_{t - 1} $ and $ x_t $ being combined using learnable parameters $ W_{hh} $ and $ W_{xh} $.
The result of this combination is then passed through an activation function to generate an output.
In a vanilla Recurring Neural Network, $ tanh $ is used for the activation function, and the hidden state is calculated by:
The prediction at time t, $ y_t $, can then be calculated from the current hidden state using a separate set of parameters:
The hidden state h, serves to maintain the 'history' of all of the inputs, as at each step the value of h is a function of all of the inputs up until that point.
Simple Example
To try and illustrate how this can work in practice, I will use a slightly contrived example, but hopefully it will help to demonstrate how we can take advantage of the history of inputs via the hidden state.
Suppose we wish to construct a very simple timer that activates after 10 steps in time.
The function will receive 1s as input, representing single steps in time, and suppose it 'activates' once its output becomes greater than 0.5.
We can model this using the following simplified RNN unit:
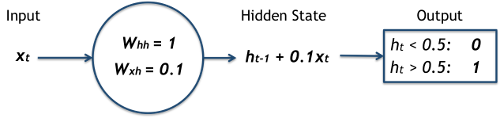
Note that this is exactly the same as in the definition of the RNN from above, setting $ W_{hh} = 1 $, $ W_{xh} = 0.1 $, and using a step function instead of $ tanh $ as the activation function.
Setting h to initially be 0, look at what happens to the hidden state and output as each step is processed:
| Step | Input | Hidden State | Output |
|---|---|---|---|
| 0 | - | 0 | - |
| 1 | 1 | 0.10 | 0 |
| 2 | 1 | 0.20 | 0 |
| 3 | 1 | 0.30 | 0 |
| 4 | 1 | 0.40 | 0 |
| 5 | 1 | 0.50 | 1 |
| 6 | 1 | 0.60 | 1 |
| 7 | 1 | 0.70 | 1 |
| 8 | 1 | 0.80 | 1 |
By incorporating all of the history of the inputs into the output of the model, it is possible to obtain this time or sequence-dependent behaviour.
(Note: in practice, due to computational restraints, it is not normally possible to process all of the input in one go, and 'mini batches' of input are typically used. Thus the value of the hidden state will be based on all of the history of the current mini-batch up until that point, rather than the history of the whole sequence.)
LSTM
I have just described what is really the simplest type of RNN unit used in practice. One of the problems with this model is that is has difficulty learning long-term dependencies within sequences.
Fortunately there are other types of Recurrent Neural Network units that are a bit more complicated to describe, but that end up being more powerful models. One such unit is called a Long Short Term Memory unit, or LSTM.
In principle, the idea is the same, whereby at each step we are just applying a recurrence relation, albeit a more complex one. Without going too much into the mathematical details, the basic setup is the following.
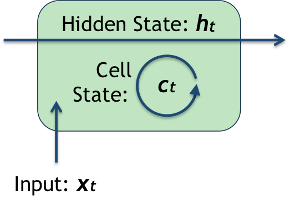
Whereas in a simple RNN we were maintaining and updating a hidden state $ h_t $ at every step, in an LSTM we keep track of two variables: the hidden state $ h_t $ along with an internal cell state $ c_t $.
The cell state works a bit like an internal memory that can 'remember' or 'forget' things as needed.
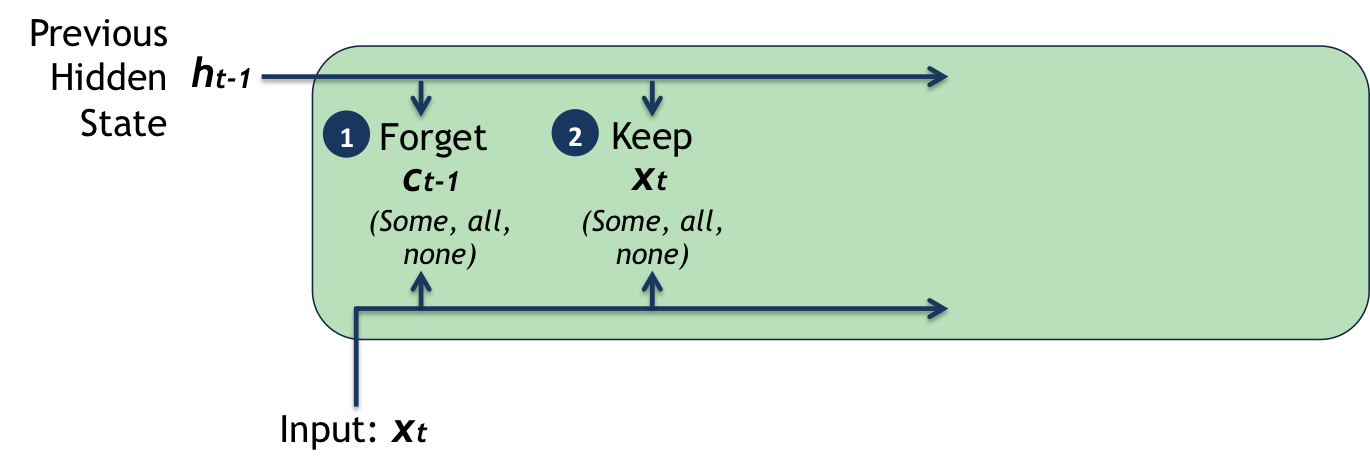
The first step is to decide how much of the previous cell state to forget. In order to do this, the LSTM looks at the incoming value $ x_t $, along with previous hidden state $ h_{t-1} $ and outputs a number between 0 and 1, where 0 means completely forget and 1 means completely remember.

The second step is to decide how much of the input to keep. Once again, the LSTM looks at the incoming value $ x_t $ and the previous hidden state $ h_{t-1} $ and decides which bits of information to keep, scaled by a certain factor.
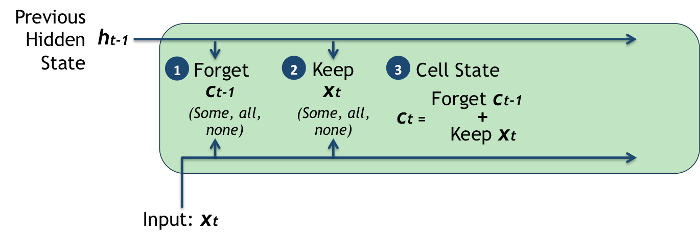
We are now in a position to update the cell's memory, or internal state, $ c_t $:
Finally, we decide how much of the new cell state we want to output, which is based on the recently updated cell state scaled by a particular factor. The scaling factor is again based on the incoming value $ x_t $ and the previous hidden state $ h_{t-1} $.
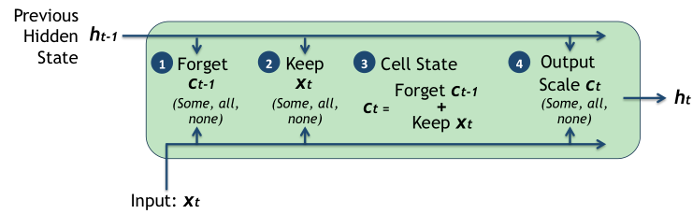
If you're feeling a bit confused at this point, don't worry. There's a lot going on and it took me quite a long time to really get my head around this model.
The LSTM can be summarized more simply:
- There is an internal cell state, or memory, c
- At each time step, the cell state is updated:
- Part of the old cell state is 'forgotten'
- Part of the new input is 'kept'
- The output of the cell is based on some of the internal state scaled in a certain way (i.e. only parts of the cell state become output)
2. Baseline Results Using Markov Chain Models
Problem Summary
Before moving on, I want to be a bit clearer about what it is that we hope to achieve. I mentioned earlier that the aim is to build a Character Level Language model, capable of generating text.
In more simple terms, this means that we want to build a model based on individual characters, for example individual letters, spaces, punctuation marks etc., that outputs a prediction for the next character based upon the current character.
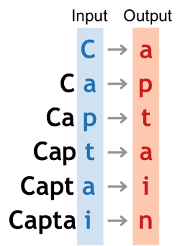
For example, if we were to start with a capital C, we might want the model to proceed as follows:
The Data
The data comes as a single 12 MB text file, containing formatted scripts complete with indentations, newlines, scene descriptions, stage directions etc.
As such, we would also hope that the model is capable of generating text that obeys the same formatting style:
7 ANGLE EMPHASIZING PICARD AND DATA
As Picard turns to Data:
PICARD
You will agree, Data, that
Starfleet's instructions are
difficult?
Markov Chain Models
It is worth noting that different types of language generation algorithms have been around for a long time, and a quite common one is based on mathematical models called Markov Chains.
A Markov Chain is a probabalistic model which has the key property that the future is based only on the present.
For example, if you were to use a Markov Chain to model some sequence $ x_1, x_2, x_3,...,x_n $, then at any given moment $ i $, the next step $ x_{i + 1} $ is dependent only upon the current state $ x_i $.
For example, a simple dice-based board game such as Snakes & Ladders is an example of a Markov Chain:
- It is probabilistic - your next position is based on the random outcome of a throw of the dice
- Your next position is only dependent on your current position; how you got to where you are now does not make any difference
Markov Chain Models in Practice
Building and using a Markov Chain for generating text is actually quite simple. For example, suppose that we start with some simple training text like:
"Captain Picard and the Enterprise"
All that is required for building a character-level model is to step through the text one character at a time and create a table of all of the pairs of characters that precede one another.
For example, for the first few characters:
'' → 'C'
'C' → 'a'
'a' → 'p'
We end up with the following table:
| Preceding | Following |
|---|---|
| '' | C |
| P | ['i'] |
| i | ['n', 'c', 's'] |
| E | ['n'] |
| t | ['a', 'h', 'e'] |
| C | ['a'] |
| s | ['e'] |
| ['P', 'a', 't', 'E'] | |
| c | ['a'] |
| r | ['d', 'p', 'i'] |
| h | ['e'] |
| p | ['t', 'r'] |
| e | C |
| d | [' ', ' '] |
| n | [' ', 'd', 't'] |
| a | ['p', 'i', 'r', 'n'] |
Generating new text is as simple as starting with a particular letter, and then using the table to identify what the next character should be at each stage. If there are multiple options we simply pick one at random.
For example, starting with the letter C, one possible output could be:
Can anteCain En teCa
It is also possible to do this using pairs of characters (i.e. 'Ca' → 'pt', 'ap' → 'ta' etc.), triplets of characters or even complete words.
Some Results
To see how well Markov Chains perform in practice, here are some results based on training the model on the complete Star Trek TNG scripts, using single characters, pairs, triplets, 4-grams and 5-grams.
In each of the following models, I attempted to generate 2,000 characters of text based upon the constructed character transition tables.
Single Character Model
STAR TREK: vero rintove is.
For the single-character model, at first the output was nearly all blank spaces. This is because, due to the script formatting, there are a lot of tabs and newlines, and so as soon as the model generates a some sort of white-space, it will almos certainly continue to follow this with more blank space.
In the end I had to feed in an initial bit of text, called a 'seed' (in this case 'STAR TREK'), in order to generate anything at all, but even here it only managed a few nonsensical characters before returning only blank space.
Pairs of Characters
RIKERTION Bould
to the ENTINUED: (OPTICASTARD
Yest ashas aways fathe the ded ing to
taptand stor
We's flicare effew am crent bel loordents.
Borgantion afteraly, airal.
Once you start using pairs of characters, the model can output text without needing a seed, however most of it just looks like nonsense.
The model does seem to start to replicate some of the formatting, such as multiple tabs and newlines, and in some cases there are the briefest hints of Star Trek, such as RIKERTION, or in other cases DATA and Borgantion.
Triplets of Characters
CONTINUED: (2)
Picard is gazing)
Here is walk me to various
ands through than assador
alling attentitly
If the recommitting all right problement in he's not the
By the time you get to using triplets of characters, most of the words are recognizably English, even if most of the sentences don't make any sense.
The formatting overall is much more script-like, and you even start to get things like:
MING STATION - ACT THREE STAR TREK: "Birthrough a feelian emember One?
which could almost be out of a Star Trek episode.
4-Grams (four characters in a row)
40 INT. REPORTER ROOM
Similar containly
me. I will not serve ident made vine of his look of your has claim, Worf?
Worf REACTS.
DATA'S VOICE
immediately that just station as both for Wesley which wears agony others at the cape (o.s.)
find here -- your name?
Radue could did the doesn't happened... so now a heavy...
RIKER
RIKER
(to Kareer...
Using 4-grams, things look even better, with line-numbers (in no particular order), and perhaps even some Klingon (K'MTAR).
5-Grams (five characters in a row)
STAR TREK: "The Pegasus" REV. 7/17/92 - ACT FIVE KAMIE USS ENTERPRISE - TRANSPORTER EFFECT stars
still accumulated the
window operation's birth...
36.
47 OMITTED
39A
39B ON ALBERT, the faction... she's heard so much a device. Finally nods. Picard leans closer... It won't belonged to get them.
No answer would
narrow-minder of Honor" - REV. 01/26/93 - ACT THREE 23.
14 INT. MAIN BRIDGE
The computer
claimed this place.
Sequences of 5-characters was the most complex Markov Chain model I built, and I think it is pretty amazing how much complexity such a simple model can generate.
Even though the sequences of words don't really mean anything, the model is capable of generating pretty-well formatted output, it includes a title, numerous line numbers etc.
Given that such a simple and easy-to-build model can perform this well, we would need an RNN-based model to do significantly better given the increased complexity and required computational power.
3. Star Trek Script Generation Using RNNs
Training Setup
In order to train an RNN using the Star Trek data, I used Torch along with a library created by Justin Johnson from Stanford University, running on an Amazon Web Services GPU g2.2x Large instance.
I experimented with a number of network parameters, including trying both simple RNN as well as LSTM units. The best results were based on a network with the following setup:
| Basic unit: | LSTM | See overview above. |
| Number of layers: | 3 | This is the depth of the network, meaning there were three layers stacked on top of each other. |
| RNN Size: | 256 | This is the number of hidden units in each layer of the network. |
| Sequence Length: | 200 | The size of the sequence used during training; as I mentioned earlier it is not feasible to train on all of the text at the same time. Here the network is trained on sequences of 200 characters. |
The remaining network parameters were based on defaults as described here.
Loss Curve
As with any suprvised machine learning problem, we already have the 'answer' that the network should output in any given situation, in this case the next character in a sequence.
During training the idea is to adjust the internal network weights in such a way as to make the actual and desired output as close together as possible. In order to do this we use a loss function that captures how 'wrong' the network is, and so the goal during training is to minimize this loss.
It is quite common to visualize how the loss evolves over time during training in order to get an idea of how the network is behaving and evolving, whether it is heading in the right direction and whether or not it seems to be improving on its results or has reached some kind of plateau (convergence).
Below is such a visualization for the best network mentioned above. The red line represents the loss as calculated on the training data being used at each iteration. The blue line represents the loss as calculated on a separate set of data used exclusively for testing or validation purposes.
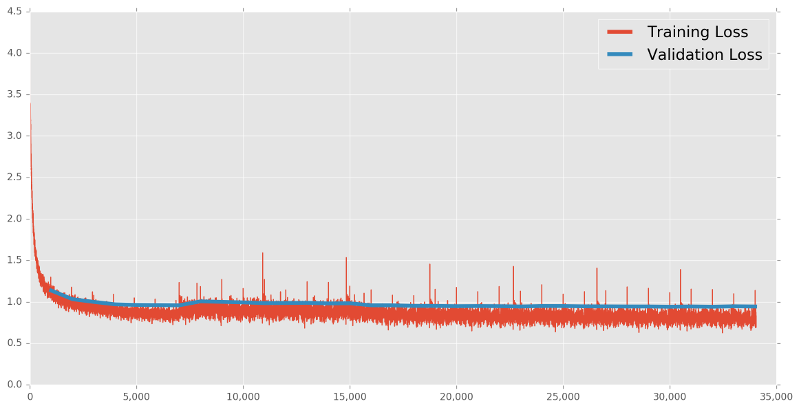
You can see that the training loss starts out relatively high and decreases pretty quickly within the first 5,000 iterations. Both the training and validation loss seem to have leveled out somewhere between iteration 5,000 and 10,000, and they only improve very slightly thereafter.
You can also see that the red and blue lines are pretty close together. This is a good thing as it is an indicator that the model is not overfitting too much on the training data and is able to generalize reasonably-well to the validation data.
The noise in the training loss is due to the fact that we are training the model using only subsets of input data, rather than all at the same time. You can imagine that for any given sequence of characters, the internal weights that minimize the output loss will probably not be the same set of weights that optimize the loss for any other sequence.
Generating Text
So what happens when we generate some text using the RNN (LSTM) model?
Before looking at some examples, I need to mention another parameter we can control while sampling called the 'temperature', which is in the range $ 0 < temperature <= 1 $.
In effect the temperature controls how risky or varied the model is in predicting new characters. When the temperature is low, the model tends to make 'safer' but more boring predictions. At high temperatures, the model will take more chances and make more varied predictions, but is also more likely to make mistakes.
Temperature = 1
49 ANOTHER ANGLE (OPTICAL)
The outing is enraged, served. Worf, Riker moving
over on a silent monitor in rage... he's admired with
various memory program. Then on his computer connects.
BEVERLY
And now! I don't reveal it
off.
WORF
Of course I small provide them.
KYLE
You don't remember it?
GUECHREY
What is that? But that's all we
do as fast...
GEOWDER
Your tent? What're has you?
I neededed get more returns to
travel.
DATA
The descepants will give no
routine incident. And that Ferengi
are over enough to assist in
Four, shuttlecraft.
Reactions. He walks off from the art of a compartment.
At the highest temperature we get some pretty well formatted text, but you can see that there are some spelling mistakes: GUECHREY, neededed, descepants.
Temperature = 0.1
PICARD
(to com)
Computer, report to the ship and
are a little second three three
hours.
PICARD
(to com)
The computer readings are all
there is a second on the ship.
PICARD
I do not know what the contract
to the ship is a little series.
PICARD
(to com)
The ship is a possible container
of the ship and the ship is a
sense of the ship and as a second
second second officers are all
there is a second officer to the
Enterprise to the Enterprise.
PICARD
(to com)
Computer, locate the ship and the
Enterprise is the ship and the
Enterprise is the ship and the
Enterprise is the ship and the
Enterprise is the ship and all
the ship is a little second three
hundred thousand three hundred
thousand three hundred thousand
that the contract with the ship
and the ship is a second on the
Enterprise.
PICARD
(to com)
The ship is a little distance of
the ship and the ship is a little
distance to the ship and the ship
is a little band of a second on
the Enterprise.
Here the model is making the safest possible predictions, and it ends up almost exclusively generating dialogue by Captain Picard (sometimes there is some Commander Riker dialogue too). It also repeats itself a lot, as if stuck in some kind of loop.
Temperature = 0.75
21 INT. NEEDED GEORDI (OPTICAL)
as he heads toward them and DROPPING SOUNDS.
DATA
Sir, that is not advantaged at
several days onboard to bodily
human are weak. We have learned
a stature of the past... literard
on the Stargazer's power range,
the Enterprise is a personal
board and transported. You lost
them estimate a logs as far and
deck enough as she fights.
RIKER
Unless the band of generators with
me in it. Only the power took a
living graviton development.
WORF
Return to your legs?
PICARD
(faster historical)
I don't think you would participate
himself.
PICARD
What he were so quite clear?
RIKER
I can't point this bad former --
much decision.
Kyle shines from his words and the shuttle at his
head.
STAR TREK: "Data's Day" - REV. 10/15/90 - ACT TWO 27.
33A CONTINUED:
PICARD
I'm sure this is that the report
knows what comes.
A pretty good sweet-spot seems to be somewhere around Temperature of 0.75, where we get quite varied output, with very few spelling mistakes.
Conclusion
Despite the fact that the model is a long way off generating a full script, or even any meaningful dialogue, I find the results to be absolutely amazing.
Remember that this is a single character model that works one letter at a time, and does not know anything about words, punctuation or script-writing rules. And yet, not only does it generate proper English words, but it also has learned a number of quite complex rules.
For a start all of the lines have almost perfect indentation and line-length:
Original Script:
PICARD
You will agree, Data, that
Starfleet's instructions are
difficult?
Generated Output:
PICARD
Begin and it has already also
get a long...
Furthermore, it has figured out that episode names have a particular format, including a name (enclosed in quotation marks), a date and an act:
Original Script:
STAR TREK: "Haven" - 7/13/87 - ACT THREE
Generated Output:
STAR TREK: "The Shroud" - 2/1/88 - ACT FIVE
It includes dialogue and scene notes and correctly opens and closes brackets:
BEVERLY
(moves quickly to Riker)
Yes, the model is a lot more complex than the Markov Chain-based models I introduced earlier, but the results are also far superior.
The single-character markov chain model was only able to generate a little bit of gibberish followed by blank spaces, and even the 5-gram Markov Chain model did not produce anything as accurate as the RNN.
Notes:
A big thanks to Andrej Karpathy for his blog post which inspired me to look at RNNs as single-character language models.
I also found Christopher Olah's blog post on LSTMs to be one of the clearer explanations out there.
Accompanying code is on GitHub.